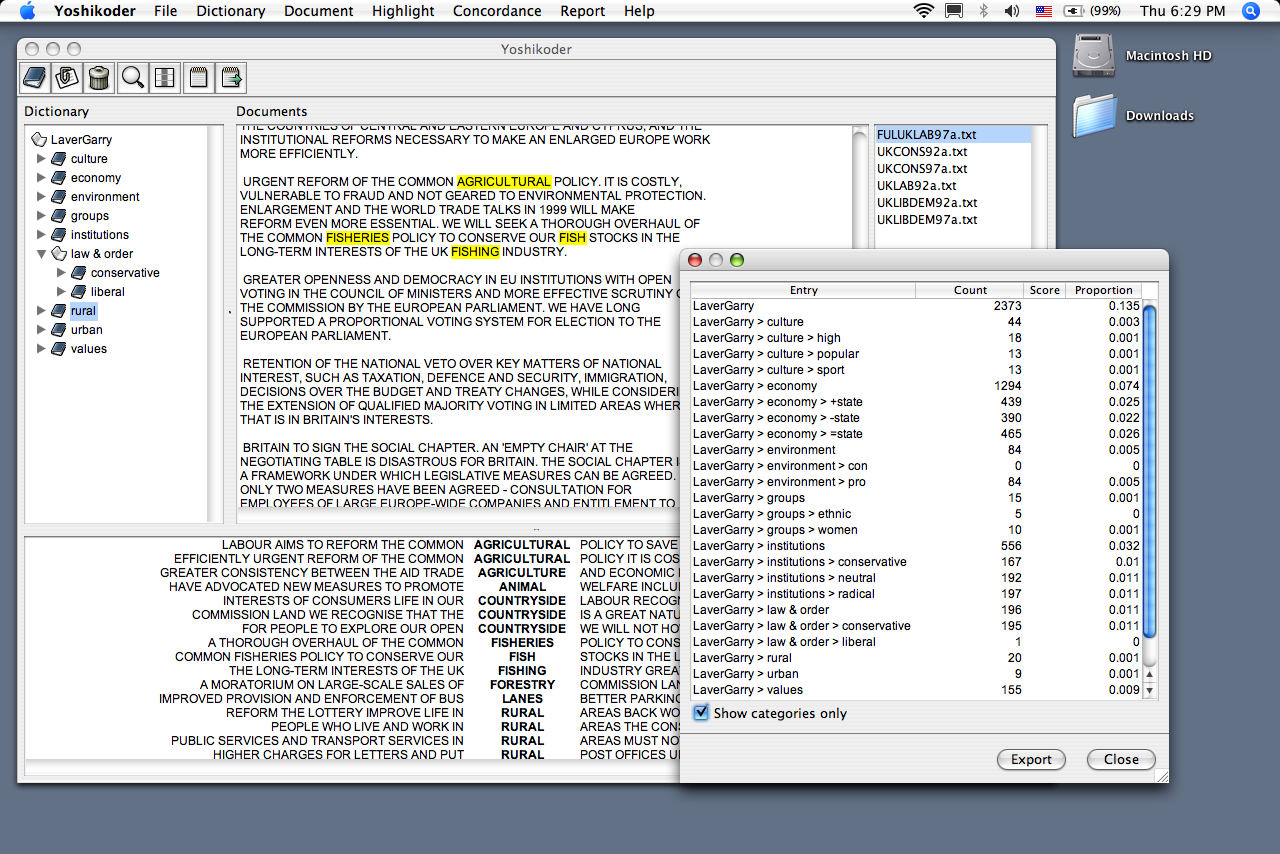
The Yoshikoder is a cross-platform multilingual content analysis program developed by Will Lowe as part of the Identity Project at Harvard's Weatherhead Center for International Affairs.
You can load documents, construct and apply content analysis dictionaries, examine keywords-in-context, and perform basic content analyses, in any language. Here's a screenshot.
The Yoshikoder works with text documents, whether in plain ASCII, Unicode (e.g. UTF-8), or national encodings (e.g. Big5 Chinese.) You can construct, view, and save keywords-in-context. You can write content analysis dictionaries. Yoshikoder provides summaries of documents, either as word frequency tables or according to a content analysis dictionary. You can also apply a dictionary analysis to the results of a concordance, which provides a flexible way to study local word contexts. Yoshikoder's native file format is XML, so dictionaries and keyword-in-context files are non-proprietary and human readable.
Development has been halted for several years now, as the author has focused on developing R packages, including contributions to the Quanteda package.
Download the latest version.
Yoshikoder is now hosted on Github. Previous versions are available from Sourceforge, though it's not clear why you'd be interested in those.
You'll need to install a runtime for Java (version 1.8 or later) to run the software - unless you're on a Mac and choose the bundled version. Instructions are at the link above.
The package is not (yet) "signed" as of late 2020, but we're working on it.
| yk2-plugin.jar | Tokenizer libraries (for tokenizer developers) |
You may need to right click to save these files.
Please note that these dictionaries are available courtesy of their authors and translated into Yoshikoder format by me. They are not necessarily in the public domain unless their authors agree, and the Yoshikoder's open source license implies nothing about what you can do with them. For all these sorts of questions, please ask the authors.
If you are the author and want to have a link updated or removed, or you want to correct a conversion error I have made, please contact me.
| laver-garry-ajps.ykd | Laver and Garry's dictionary, from 'Estimating policy
positions from political texts', American Journal of
Political Science 44 pp.619-634. Note This dictionary supercedes previous dictionaries mounted here. |
LIWC |
The Linguistic Inquiry and Word Count dictionary is available, for research purposes only, directly from: James Pennebaker. See also the LIWC homepage |
| RID-en.ykd | Colin Martindale's Regressive Imagery Dictionary (English). All versions of the RID on these pages are translations of the Wordstat files at Provalis Research. |
| RID-fr.ykd | Regressive Imagery Dictionary (French) translated by Robert Hogenraad |
| RID-pt.ykd | Regressive Imagery Dictionary (Portugese) translated by Tito Cardoso e Cunha, Brigitte Detry, and Robert Hogenraad. |
| RID-sw.ykd | Regressive Imagery Dictionary (Swedish) translated by Torsten Norlander, Moira Linnarud, Marika Kjellén-Simes, and Robert Hogenraad. |
| RID-de.ykd | Regressive Imagery Dictionary (German) translated by Renate Delphendahl. |
| bara-et-al.ykd | The dictionary used in Bara, Weale and Biquelet (2007) 'Analysing parliamentary debate with computer assistance' Swiss Political Science Review 13(4). |
| nd_finance.ykd | A collection of word lists from Bill McDonald for processing financial reports. |
The Yoshikoder can use plugin tokenizers for languages where
built-in tokenization is insufficient. Currently an
experimental tokenizer plugin for simplified Chinese is
available - based on code by Erik Peterson.
| SCTokenizer.jar | for Simplified (Mandarin) Chinese |
If you'd like to refer to the package in written work (and you should) you can use this:
Will Lowe (2015) 'Yoshikoder: Cross-platform multilingual content analysis'. Java software, version 0.6.5, URL: https://yoshikoder.org
Development has been kindly supported by the Weatherhead Center for
International Affairs, and the Institute for Advanced Study.
In addition, the following open source tools were
invaluable for writing the Yoshikoder.
| Eclipse | an integrated development environment |
| Ant | a Java build tool |
| Apache POI | for reading and writing MS Office files |
| BrowserLauncher2 | for launching browsers |
| Quaqua | for OSX platform integration |
| MRJ Adaptor | for OSX specific features |
| Jarbundler | for making OSX application bundles |
| launch4j | for making Windows executables |
You might find the Yoshikoder Converter useful for converting web, MS Word and PDF documents into plain text before analysis.
The Yoshikoder is licensed under the Gnu Public License. This means you can do essentially anything you like with the software, except sell it as your own.
In no particular order...